

Traditional machine learning models, such as decision trees, random forests, and support vector machines (SVMs), were widely used for structured data analysis. However, with the rise of deep learning, more sophisticated architectures have emerged, such as Convolutional Neural Networks (CNNs) for image recognition, Recurrent Neural Networks (RNNs) and Long Short-Term Memory (LSTM) networks for sequential data, and Transformers for natural language processing (NLP).
CNNs have transformed computer vision applications, enabling AI to recognize objects, detect faces, and classify images with high accuracy. Unlike traditional models, CNNs use convolutional layers, pooling layers, and fully connected layers to extract hierarchical features from images. This has led to innovations in autonomous driving, medical imaging, and surveillance systems. Similarly, RNNs and LSTMs have been instrumental in speech recognition, time-series forecasting, and chatbots, as they can process sequential data efficiently.
However, one of the most significant breakthroughs in AI architecture has been the rise of Transformers, such as BERT (Bidirectional Encoder Representations from Transformers), GPT (Generative Pre-trained Transformer), and Vision Transformers (ViTs). Unlike traditional sequential models, Transformers use self-attention mechanisms, allowing them to process entire data sequences in parallel. This has dramatically improved performance in machine translation, text generation, and multimodal AI, where models can process both text and images simultaneously.
To optimize these architectures, researchers have developed techniques such as pruning, quantization, and knowledge distillation. Model pruning reduces the number of parameters in a neural network, making it more efficient without sacrificing accuracy. Quantization converts model weights into lower precision formats, enabling deployment on edge devices with limited computational power. Knowledge distillation involves training a smaller model using the knowledge from a larger, pre-trained model, which helps in deploying AI solutions on resource-constrained devices like smartphones and embedded systems.
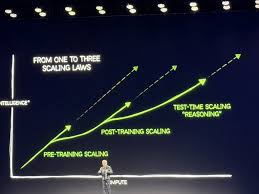
With the evolution of AI architectures, the focus is now on developing more efficient, interpretable, and scalable models that can generalize well across different domains. This includes few-shot learning, zero-shot learning, and federated learning, which allow AI models to learn with minimal labeled data and enhance privacy by training on decentralized data sources. The future of AI model architecture is geared towards making AI more efficient, accessible, and adaptable across diverse industries.








Leave a Reply